
Now that we’ve covered how performance metrics have evolved over time, in this second post of a series about Application Performance Monitoring (APM), we discuss what APM is and why we need it.
Posts in this series:
- Application Performance Monitoring: A Performance Metrics Refresher
- Application Performance Monitoring: What and Why?
- Application Performance Monitoring: Options for Everyone
What is Application Performance Monitoring (APM)?
In the wild, the M in the APM acronym can refer to both monitoring and management. Most people consider application performance monitoring a subset of application performance management. According to Wikipedia,
Application performance management (APM) is the monitoring and management of performance and availability of software applications. The purpose of APM is to detect and diagnose complex application performance problems to maintain an expected level of service. APM is the translation of IT metrics into business meaning or value.
APM can help do several key things:
- Measure and monitor application performance.
- Find the root causes for application problems.
- Identify ways to optimize application performance.
To get more granular, here is a definition of APM according to Gartner, a technology research firm. APM is one or more software (and/or hardware) components that facilitate monitoring to meet 5 main functional dimensions:
- End-user experience monitoring - capturing the user-based performance data to gauge how well the application is performing and identify potential performance problems.
- Application topology discovery and visualization - the visual expression of the application in a flow-map to establish all the different components of the application and how they interact with each other.
- User-defined transaction profiling - examination of specific interactions to recreate conditions that lead to performance problems for testing purposes.
- Application component deep dive - collection of performance metrics pertaining to the individual parts of the application identified in the second dimension (the visualization of the application).
- IT operations analytics - discovery of usage patterns, identification of performance problems, and anticipation of potential problems before they happen.
Application Performance Metrics
So how do we measure performance over time? Here are some key Application Performance Metrics as defined by Stackify, a devops tools company:
- User Satisfaction / Apdex Scores
- Average Response Time
- Error Rates
- Count of Application Instances
- Request Rate
- Application & Server CPU
- Application Availability
User Satisfaction / Apdex Scores
Let’s start with the first key metric in the aforementioned list. An Apdex score is an application performance index. According to Wikipedia,
Apdex is an open standard developed by an alliance of companies. It defines a standard method for reporting and comparing the performance of software applications in computing. The purpose of Apdex is to convert measurements into insights about user satisfaction. This is done by specifying a uniform way to analyze and report on the degree to which measured performance meets user expectations.”
Here is a definition of Apdex according to New Relic, a popular enterprise APM solutions company:
Apdex is an industry standard to measure users' satisfaction with the response time of web applications and services. It's basically a simplified Service Level Agreement (SLA) solution that gives application owners better insight into how satisfied users are.”
Apdex is a measure of response time based against a set threshold. It measures the ratio of satisfactory response times to unsatisfactory response times. The response time here is measured from an asset request to completed delivery back to the requestor.
Web requests are separated into satisfied (fast), tolerating (sluggish), too slow, and failed requests. A simple math formula then provides a score from 0 to 1.[1] Here’s the visual representation of the Apdex formula:

The Apdex score is a ratio value of the number of satisfied and tolerating requests to the total requests made. Each satisfied request counts as one request, while each tolerating request counts as half a satisfied request. So an Apdex score varies from 0 to 1, where 0 is the worst possible score and means 100% of response times are Frustrated. Whereas 1 is the best possible score which means 100% of response times are Satisfied.[2]
For an example taken from NetworkWorld, say we’re working with 100 samples with a target time of delivery within 3 seconds.
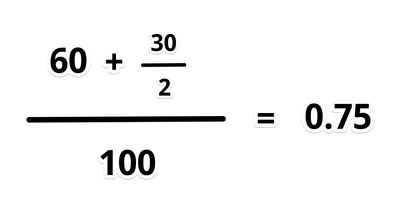
Of that 100 samples, 60 are below 3 seconds, 30 are between 3 and 12 seconds, and the remaining 10 are above 12 seconds. When we plug the numbers into the Apdex formula, we end up with an Apdex score of .75. Hopefully Apdex scores make sense as a way for understanding and measuring user satisfaction.
Average Response Time
Average Response Time is the amount of time an application takes to return a request to a user. To measure Average Response Time, an application should be tested under different circumstances (i.e. number of concurrent users, number of transactions requested).[3]
Typically, this metric is measured from the start of the request to the time the last byte is sent. Keep in mind that we should take caution in its accuracy. Other factors, like geographic location of the user and the complexity of the information being requested, can affect the average response time for users. These should all be considered in the overall evaluation of application performance. Graphically, you can understand average response time like a bell curve - so it can be skewed by a few very long responses.
For the rest of the key APM metrics, Stackify does a nice job of describing them in detail so I’ll leave this list with one final thought on the subject:
All metrics should be evaluated over time, and one that is critical should be fed into a rules engine that raises alerts when a set threshold is exceeded. Ultimately all metrics can and should be used to understand what is normal/typical for your application so that abnormal/atypical behavior can be detected.
Now let’s move onto what actually comprises an APM solution.
APM Solution components[4]
- An APM solution should allow you to analyze the performance of individual web requests or transactions.
- It should enable you to see the usage and performance of all application dependencies like databases, web services, caching, etc.
- It should let you see detailed transaction traces to see what your code is doing.
- It optimally provides code level performance profiling.
- It should have basic server metrics like CPU, memory, etc.
- It should have application framework metrics like performance counters and queues.
- It should allow dev teams or from the business side, product owners, to create and customize metrics.
- It should enable you to aggregate, search, and manage your logs.
- It should allow you to set up robust reporting and alerting for application errors.
- It should facilitate real user monitoring to see what your users are experiencing in real time.
Custom Metrics
Let’s take a moment to talk about at custom metrics. There are 3 typical ways in which custom metrics are applied:[5]
- Sum or Average which can be used to count how often a certain event happens.
- Time – monitor how long transactions take.
- Gauge – track concurrent operations or connections.
Good enterprise APM solutions should allow customers to create and apply custom metrics. One way we did this recently on a client site was to track deployments so that we could see in real time how deployments affect end-user response times. This is enormously helpful to see right away how to pinpoint problems when new code is introduced.
APM Best Practices
As far as best practices go with respect to APM, here's a helpful short list[6] as defined by Monitis, a software-as-a-service (SaaS) performance monitoring platform:
- Plan and configure alerts that work for you.
- Set priorities to classify your systems based on importance.
- Never Allow a Single Point of Failure.
- Know who to contact and how to contact them most effectively.
- Periodically verify and test your alerting and escalation protocols.
- Never set up email filters for your alerts.
- Creating a process on how alerts are resolved.
- Ask for help from your vendor.
- Document. Document. Document.
How APM saves day after day
In the course of my time as a developer, I've become an unabashed APM evangelist with the firm belief that a robust APM solution is worth its weight in gold. For our enterprise clients, it's absolutely critical in order to identify and solve issues in their complex codebases, especially as we developers roll out new features and functionality. From troubleshooting small problems to pre-empting big ones, having a good APM solution in the arsenal can save countless hours, headaches, and dollars.
For a case study in how APM helped us solve a really hard problem, check out my post The Tipping Point of a Flooded File System. At the time, I was working on the dev team for a major online content publisher whose site runs on Drupal 7. During my time on that project, we encountered a strange phenomenon that was perplexing to all of us. While I didn't go into very much detail about how we leveraged APM in that particular article, I can tell you that without APM, we would have been stuck in complete darkness spinning our wheels.
For that particular client site, page loads were decent - around 700 ms (that’s 7/10 of one second). In spite of this we were still getting alerts from the APM application that something strange was afoot. It motivated us to try to get to the bottom of what was happening. Because of the granularity with which we could drill down into the APM interface, we could see which transactions were taking way too long. Based on what the APM data was telling us, we began a process of deeply examining the application, analyzing its queries and longest transactions. We did everything we could to eliminate inefficiencies wherever we found them.
By monitoring our client's Apdex scores over time, all the work we put into optimizing the code base and cleaning up slow queries helped to get the application back on track and the frequency of the alerts dropped which was a huge relief.
Even more exciting, we ended up significantly improving page load speed. All our efforts to troubleshoot the alerts lead to a phenomenal decrease in page load time from 700 ms to an average of 200 ms. We reduced page load time by over 70%.
Needless to say, our client was thrilled - not only did we resolve the mysterious performance alerts, but all our work which was informed by the APM tool, lead to a tremendous gain in performance.
Now that we know what APM is and why we need it, check out the last post in this series, Application Performance Monitoring: Options for Everyone, to find out what APM tools are available for your budget.
Footnotes
8 Key Application Performance Metrics & How to Measure Them ↩︎
6 Critical Web Application Performance Metrics to Consider ↩︎
What is Application Performance Management? Overview, Common Terms, and 10 Critical APM Features, What is Application Monitoring? ↩︎
10 Tips for Monitoring Best Practices (Alerting and Notifications) ↩︎



