
Deploy Everywhere
I've written before about my search for a way to create a satisfactory local development environment. Among the pre-configured solutions I've tried, I still really like Drupal VM, but there's an issue that no out-of-the-box solution I've encountered can solve. That issue is that we often treat production deployments as something to be developed and implemented separately from development. I'd like to see that change.
One reason I'd like to see this change is because while the problem of building a local environment for code to run in has largely been solved with virtual machines and containers (there are many local development options), the configuration of the application (Drupal, for example) on the local machine still often incorporates manual steps such as importing databases, or pasting database credentials into configuration files.
Another reason I'd like to see it change is because it's a solved problem. We already routinely use automation to perform all of the steps that are needed to get a Drupal site up and running on a server as part of CI/CD processes or to provision new servers. From beginning to running site, the basic requirements to get a Drupal site running in a new server are roughly:
- Provision a server
- Install & configure packages and services,
- Start services
- Deploy Drupal
- Deploy codebase to server
- Run build tasks (e.g. Composer/npm/Gulp/Grunt)
- Create or customize settings file
- Import database dump
- Run Drupal tasks (e.g. Drush)
One way or another, we already use automation to do all of these things (and more) on our production servers.
So knowing that all the component parts for a solution to the problem already existed, I created a proof-of-concept to illustrate one way to solve the problem (but please note: this is not a complete solution, or a tool you can simply begin using). To do this, I used tools that I'm familiar with, Vagrant and Ansible (note that as I mentioned above, there are multiple solutions to each part of this problem—I'm sure the same thing could be achieved with e.g. Chef and Docker).
Requirements gathering
The basic approach I wanted to try is quite simple: treat the local environment exactly like production. In other words, I wanted to build a development environment that not only resembled production, but was similar enough to it that I could use exactly the same process to set up, modify, or rebuild my development server as I would for one of our in-production servers.
So given that we use Ansible for many of our automation needs at Chromatic, I decided to use Ansible and Vagrant so that I could build as close a copy of a production environment as possible, and use our usual tools to provision that environment and deploy Drupal.
Putting all the parts together, our requirements are:
- An application to build
- A Vagrantfile that provides:
- A development server
- A simulated production server (to simplify the demo)
- An Ansible playbook that can:
- Run server configuration and/or application deployment
- Run tasks on development and/or production
- Provide host-specific values (including secrets!) to tasks
Creating a Vagrantfile to provide two servers (one for development, and one to simulate a remote production server) is straightforward, and this post is long enough, so I won't spend any time on that here (see Vagrant’s extensive documentation). It's the three specific requirements of the Ansible playbook that make or break the solution. Fortunately—spoiler alert!—Ansible includes features that make all of these things not only possible, but reasonably easy to achieve. Let's consider each in turn.
Meeting the requirements
Run server configuration and/or application deployment
It's not necessarily desirable to revisit the entire server provisioning process every time we publish a small code change to the site. So this means we need a way to target only the server configuration tasks or only the deployment tasks. And of course we should also be able to target both at once. Ansible's tags enable this by making it possible to limit the tasks run to one or more specified tasks.
The deployment.yml playbook contains two "plays," one to provision the hosts, and another to deploy the site to them. Each play contains a block like this:
tags:
- deploySpecifically of note is that the "Provision hosts" play uses the "provision" tag and the "Deploy application" play uses the "deploy" tag. These two tags alone provide the following options for us:
- Deploy and provision both hosts:
ansible-playbook deployment.yml - Only provision both hosts:
ansible-playbook deployment.yml --tags=provision - Only deploy to both hosts:
ansible-playbook deployment.yml --tags=deploy
So it's possible for us to target either or both plays in the playbook at will.
Run tasks on development and/or production
Each play in the deployment.yml playbook, also contains the following identical block:
hosts:
- deploy_dev
- deploy_proddeploy_dev and deploy_prod are groups of hosts defined in our hosts.yml file (in this instance, each group only contains one host). Similarly to tags, Ansible's groups allow us to limit what the ansible-playbook command does, except in this case, we can limit what hosts the playbook runs on:
- Deploy and provision both hosts:
ansible-playbook deployment.yml - Provision and deploy development only:
ansible-playbook deployment.yml --limit=deploy_dev - Provision and deploy production only:
ansible-playbook deployment.yml --limit=deploy_prod
Again, using the --limit flag, we can run the playbook against any combination of hosts.
Provide host specific values to tasks
Finally we come to what is arguably the most crucial of our three main requirements. There are many sorts of environment-specific variables that we may want to set on different hosts. For example in Drupal, we may want to provide different values for $settings['trusted_host_patterns'], or a different set of database credentials.
Using a feature rather like PHP's class autoloading, Ansible is able to automatically load variables specific to a single host. If a file or folder with the name of one of the groups defined in hosts.yml exists in the group_vars directory, its contents are automatically made available to the playbook when it runs on hosts in that group. Besides custom groups defined in inventory, Ansible also includes two default groups, all and ungrouped.
This means we can target variables very precisely to individual groups (and also to nested groups, though that's beyond the scope of this post). In the repo, the group_vars folder has the following structure:
group_vars
├── all
│ ├── common.yml
│ └── vault.yml
├── deploy_dev.yml
└── deploy_prod.ymlSo this means, for example, that when running tasks on the deploy_dev group, variables from all/common.yml, all/common/vault.yml, and deploy_dev.yml are available for use in tasks, but the variables in deploy_prod.yml are not. To see what differs between dev and prod in the repo, just compare the deploy_dev vars file to the deploy_prod vars file.
What about the secrets?
In the original list, I specified that our solution needed to "provide host-specific values (including secrets!) to tasks." If you inspect the contents of vault.yml, you'll find something a bit odd—apparently an encrypted blob!
$ANSIBLE_VAULT;1.1;AES256
30346634326166343330643433383738313666636566373230353837356533323562306232393963
3430316633373161313165623239386632623036666532370a313731613837303966336531623566
34643832313465626364643435633935313131306437386235373836303936393037373266396535
6463303132363939380a373232383935343862346339613534653633316661323136353233346239
66616239316538373435393039653630386236356135643866663932313165306432363164643030
32396262353662623339346132333333356335653633316633613161626337303465363761633836
33633165373434386532303739343330633434376639313133633138633035386261613630316536
33613537333832663534We're using this file to store site-related secrets in the repository using Ansible Vault. This isn't necessary, but to achieve the one-step build described here and demonstrated in the repo, Ansible must have a way to read and write secrets such as database credentials or (as in this case)basic authentication passwords.
Deployment tasks and what would Drupal do?
Having theoretically satisfied the requirements, let’s run a deployment. The fastest way to do this is to use the quickstart.sh script in the repo (note that you must have all of Ansible, Vagrant, VirtualBox, vagrant-hostsupdater, and vagrant-vbguest installed). Follow these steps:
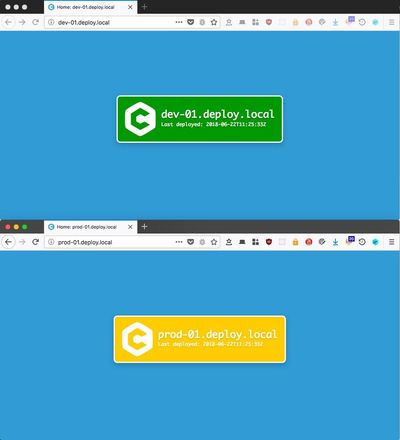
git clone git@github.com:ctorgalson/deploy-everywhere.gitcd deploy-everywhere && ./quickstart.shansible-playbook deployment.yml --limit=deploy_prod- Visit http://dev-01.deploy.local in the browser (use deploy-dev and depl0y to enter)
- Visit http://prod-01.deploy.local in the browser
Once those tasks are complete (on an older Macbook Air, this takes around six minutes for me), you should see two similar but different pages:
To finish up our look at deployments, we'll take a short look at the contents of the deploy-app.yml tasks file. This file runs eight tasks:
- Check if
node_modulesexists (on local machine) - Run
npm installif it doesn't (on local machine) - Run
gulp build(on local machine) - Use
rsyncto copy files to prod only (Vagrant handles this on dev) - Create customized
index.htmlfile on each host - Download the new
index.htmlfile from each host - Verify that the http status code from step 6 was
200for each host - Verify that the timestamp in
index.htmlmatches Ansible's for each host
Even though this is a simple, static site, the build-and-deploy process is very similar to database-driven systems like Drupal. At the beginning of this post, I summarized a Drupal build in five steps:
- Deploy codebase to server
- Run build tasks (e.g. Composer/npm/Gulp/Grunt)
- Create or customize settings file
- Import database dump.
- Run Drupal tasks (e.g. Drush)
Steps 1-4 in app-deploy.yml map neatly onto steps 1-2 of the list above, though the order is different (in app-deploy.yml, we're simulating the process of running a complete build on a build server and then deploying the resulting code; sometimes it's just as easy to build on the destination server). Ansible also provides the composer module and the command module which are both useful in Drupal builds.
Step 5 in app-deploy.yml is identical to step 3 above in every respect but the specific file. In combination with group_vars and Ansible Vault, it's easy to see how we could use the same strategy to vary the content (or output separate versions of) settings.local.php in a Drupal context.
In app-deploy.yml, we don't do anything comparable to importing a database, but Ansible has tools that make this fairly easy. Use the get_url module or the copy module to move a sql dump onto the server, then use either the command module or the mysql_db module:
# Use mysql_db module:
- name: Import db dump
mysql_db:
name: drupal_db
state: import
target: /tmp/drupal_db-20180622.sql
# Use command module (requires drush!):
- name: Import db dump.
command: "drush sql-cli < /tmp/drupal_db-20180622.sql"
args:
chdir: "/var/www/drupal/web"Finally, though app-deploy.yml doesn't need to run any shell commands (since it's just an html page...) Drupal does. We need to update the database, clear caches etc. Fortunately, as the above database import command shows, adding drush commands to a playbook is very simple.
Bonus—git hooks!
There's one final feature that I've added to the proof-of-concept repo to show one of the real benefits of setting up projects to use production deployment processes on local development machines; I've added a pre-push Git hook. If you haven't used them before, Git hooks provide "…a way to fire off custom scripts when certain important actions occur." They can be extremely useful for performing tasks such as linting before commits, or running tests.
Git hooks however are not copied when repositories are cloned (among other reasons, one should consider the security implications). But it's possible to add them to a repository and then manually enable them with a symlink. In this repo, there is a .githooks/ directory containing one hook—an ordinary bash script—that runs at the beginning of the git push command.
The hook essentially consists of this command which tells Vagrant to re-provision the dev server, passing the tag deploy to Ansible:
VAT="deploy" vagrant up --provision devIn other words this script, which runs every time a git push command is issued, runs the same deployment tasks as are run on production against the dev server, and prevents the push if the script fails. So in our search for a way to 'treat local exactly like prod', we've also found a way that the production deployment can be tested with every important code change (note: a hook can be skipped by passing -n or --no-verify to the relevant command).
To test it (you'll need to fork the repository first), symlink it into place with ln -s .githooks/pre-push .git/hooks/pre-push, make a change to the repository, commit it, and run git push.
Concluding remarks
I'm pretty enthusiastic about this method not just of structuring development environments, but of setting up entire projects. The server code can be committed to the project repository and shared with the entire development team, the modification to the workflow provides an early warning to developers when code changes threaten the production build, and the workflow completely eliminates certain classes of problems (e.g. using this workflow with encrypted secrets, changing a production server's database password requires a one line code change, and a one-line deployment). On top of all that, it doesn’t interfere if one or more stakeholders wants to use some other system.
But we need to consider the possible objections to adopting this as a workflow: is it:
- possible?
- effective?
- practical?
- universal?
- secure?
Regarding possibility, I think the proof-of-concept repo, and the day-to-day use of similar Ansible tasks in production show that it's at least possible.
In terms of effectiveness, I also think that the proof-of-concept tidily solves my initial problem of having to set up and run deployments on local and remote servers with different tools and processes.
In my opinion, this solution also scores well for practicality, though here is where I see some of the more convincing objections. First, it's arguably somewhat more complex than other local development solutions (there are a lot of files in the repo's devops/ directory!) To this objection I answer we have to create the deployment automation anyway. Frequently to two or more remote environments once QA and Prod are considered. Adding local into the mix is not a lot of extra work.
Still on the subject of practicality I admit to not being completely satisfied with the local software stack. Though I use this same stack daily, the interaction of Vagrant, VirtualBox, NFS and other components is sometimes prone to unexpected problems (certain Vagrant boxes for instance seem to provoke kernel panics). These kinds of problems haven't actually kept me from working on this in spite of the myriad of other local development solutions available though, so this might not be that strong an objection. And besides there are VirtualBox alternatives that I could explore.
With respect to universality, as far as I can tell, this is not a universally applicable pattern. It's best suited to the more or less monolithic LAMP server pattern. The greater the degree to which a project departs from that pattern, the less applicable I think this will be.
However it's worth noting that for projects where this does work, it has a good chance of literally working everywhere: development, production, CI, tests (though Vagrant can't run in Travis CI), and in git hooks.
Lastly, I don't see any particular reason to doubt the security of this as a workflow. The most unrealistic thing about this repository is the idea that individual developers would or should deploy directly to production from a workstation. But we already handle this class of problems with deploy keys at GitHub or in other services. Otherwise, this workflow is simply not very different from what we do already.
If you've made it all the way through this post, congratulations! I hope you've found it useful or at least informative. If you have questions or comments, reach out to us on Twitter at @ChromaticHQ or to me at @bedlamhotel.

